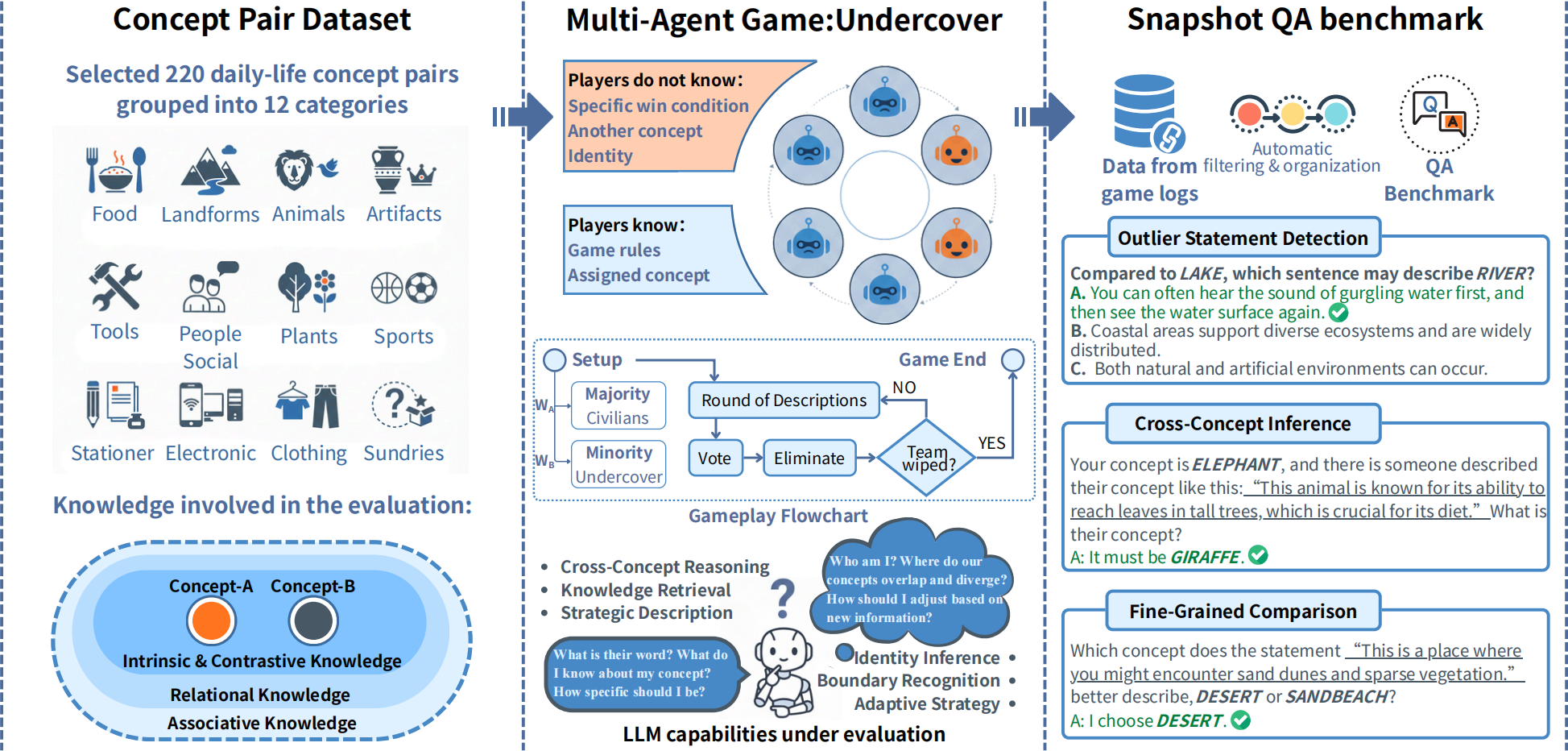
Below is an interactive demonstration of the Undercover game used in CK-Arena. We first introduce the basic game rules to help you understand, and then demonstrate the interaction of intelligent agents in the first round of a real experiment. In this game, LLM agents are assigned either the main concept ("bee") or an undercover concept ("butterfly"). Players take turns making statements about their concept without revealing it directly. The goal for the civilians is to identify and eliminate the undercover agents through voting, while undercover agents try to blend in without being detected.
Game Flow :
1. Role Assignment:
Players are randomly assigned as civilians or undercover agents, each receiving a similar but distinct concept.
2. Concept Description:
In each round, players take turns describing their concept while trying to hide their identity and infer others’.
3. LLM Evaluation:
Statements are scored by LLM judges based on novelty, relevance, and reasonableness.
4. Threshold-Based Elimination:
If a player’s score falls below a predefined threshold, they are automatically eliminated.
5. Voting Round:
After a fixed number of rounds, all surviving players vote to eliminate one player based on the dialogue so far.
6. Win Condition Check:
The game ends when:
[All undercover agents are eliminated → civilians win]
[Undercover agents equal civilians → undercover wins]
[Maximum number of rounds is reached]
News
| # | Model | Vendor | Attributes | Score | Rating Bar |
|---|
Leaderboard updated 2025-03-18 • Each player starts at 0; consistently defeating 0-rated opponents converges to ~420 (strong-performance reference).
Abstract
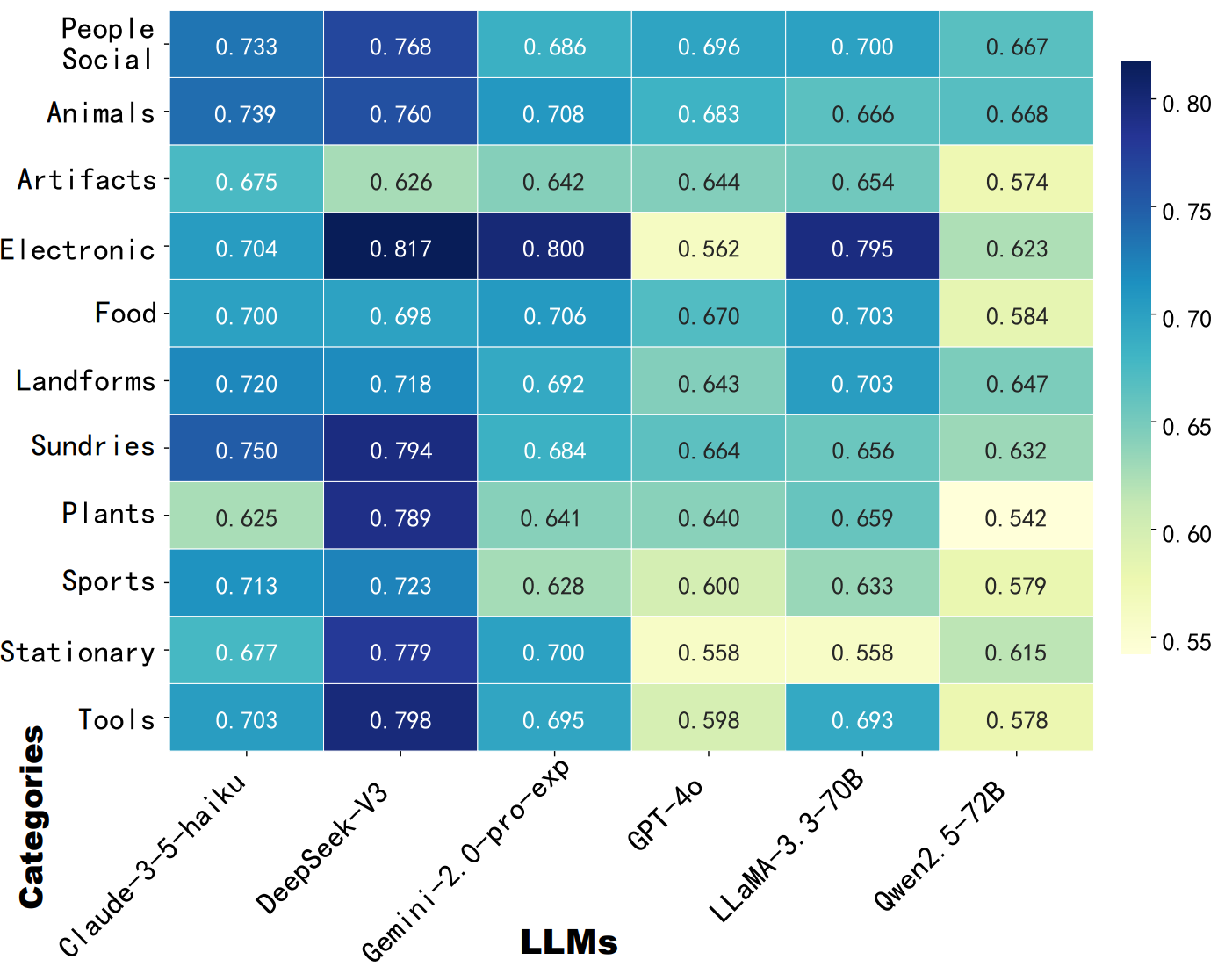
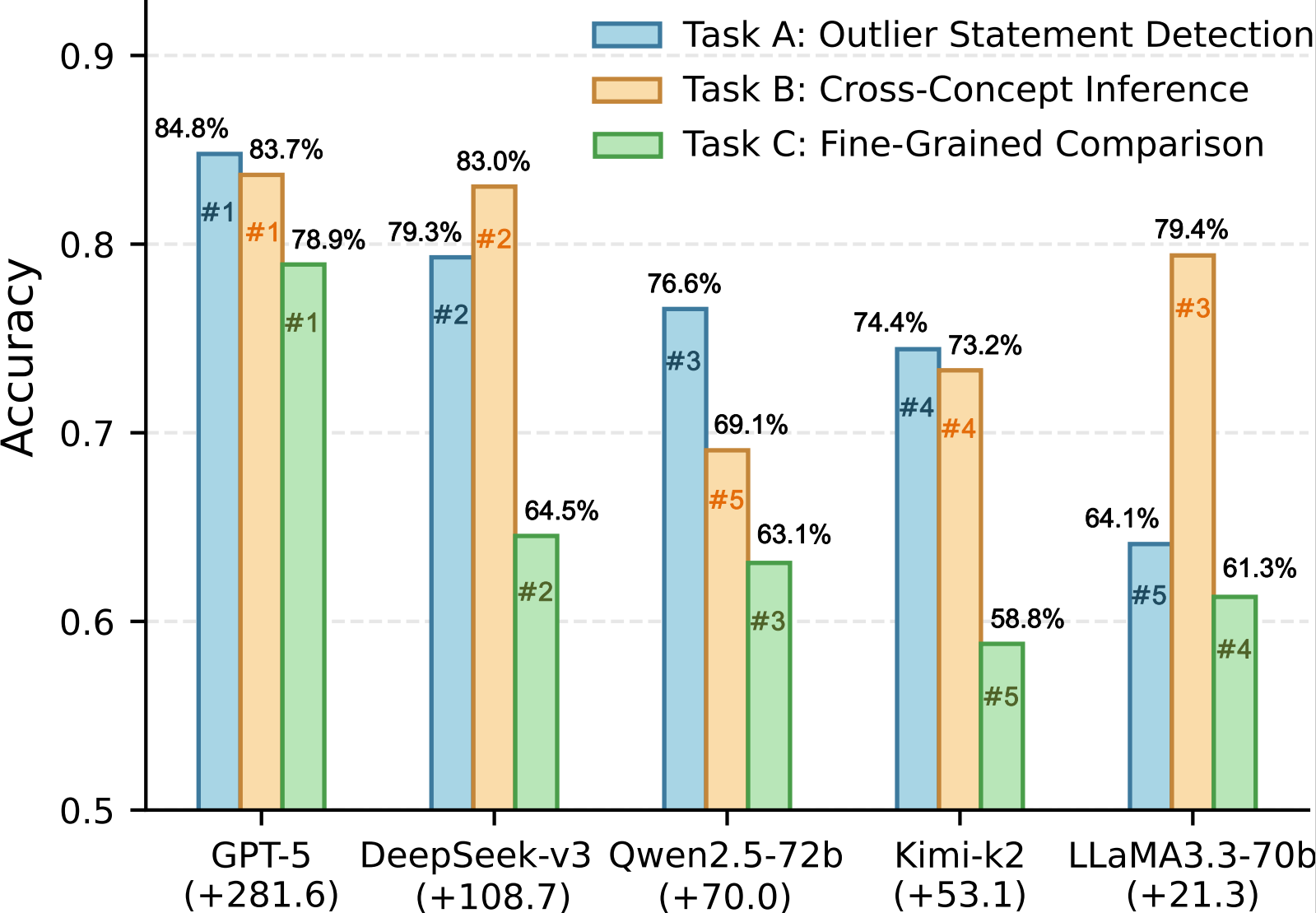
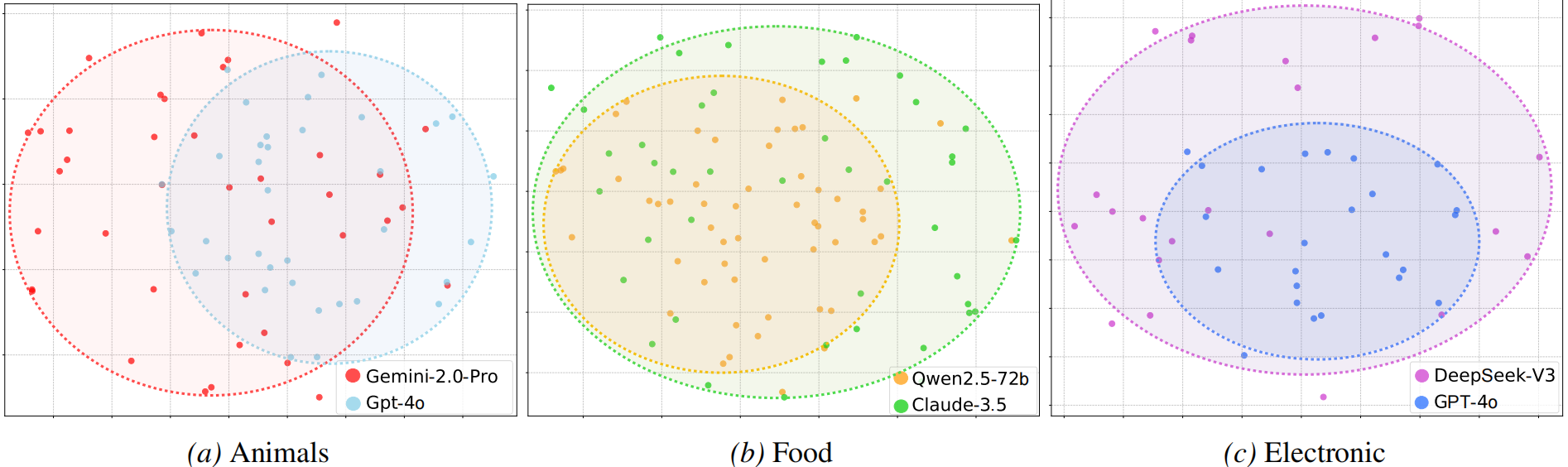
Concepts serve as fundamental abstractions that support human reasoning and categorization. However, it remains unclear whether large language models truly capture such conceptual structures or primarily rely on surface-level pattern memorization. Existing benchmarks are largely static and fact oriented, which limits their ability to probe fine-grained semantic understanding and makes them vulnerable to data leakage and overfitting. To address this limitation, we introduce CK-Arena, a dynamic benchmark for conceptual knowledge evaluation based on a multi agent social deduction game, namely the Undercover game. In this setting, LLM based agents are assigned subtly different concept words and must describe, distinguish, and infer conceptual properties from others’ statements. Model performance is evaluated through both game level outcomes and the semantic quality of generated descriptions. Furthermore, CK-Arena leverages the interaction process to automatically construct high quality question answering data for fine grained diagnostic analysis. Experimental results show that conceptual understanding varies substantially across models and categories, and is not strictly aligned with overall model capability.